What are GANs and what real-world purposes do they serve?

GAN stands for “generative adversarial network.” GANs are a class of machine learning frameworks that were invented by Ian Goodfellow during his PhD studies at the University of Montreal.
What’s so interesting about them? Before GANs, deep learning has been making progress mostly thanks to discriminative models – that is, roughly speaking, models that are able to tell things apart (as in AI being able to tell apples from oranges). Models that replicate things – generative models – were difficult to create for a variety of reasons.
Ian Goodfellow and his colleagues attempted a fresh take on the problem. They thought, “What if we let a generative model learn off of a discriminative model through an adversarial process?” (The term “adversarial” points to the fact that there is some competition involved.)
In a GAN, we have two models, the Generator (G) model and the Discriminator (D) model, that are being trained simultaneously. They compete against each other in a sense that model G tries to emulate real-world samples as closely as possible, while model D tries to predict whether the sample it’s looking at came from the training set or was created by model G.
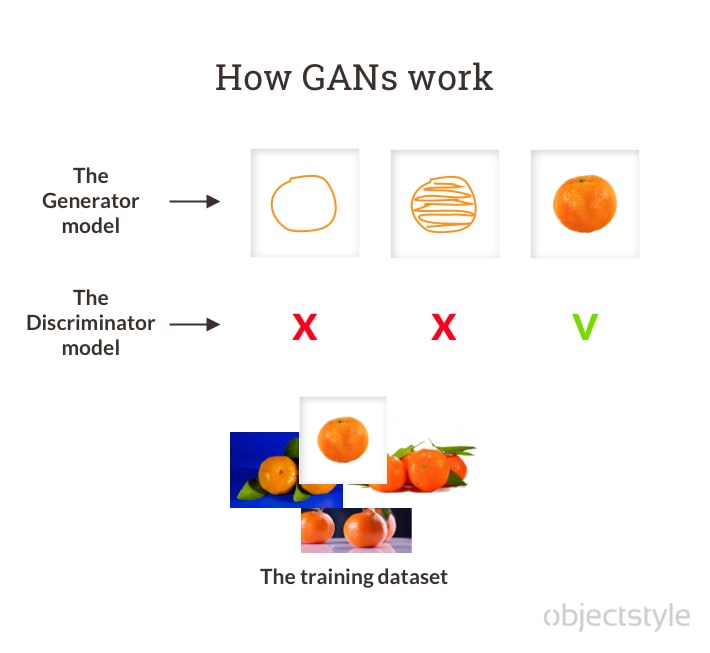
When model G becomes so good that model D can no longer tell fakes from original samples, it’s game over and the equilibrium has been reached.
The evolution of GANs
Since their inception in 2014, generative adversarial networks have come a long way in their development. Modern GAN programs are able to produce data that is so realistic-looking, it gives you the chills:

When Ian Goodfellow and his colleagues described the first-even GAN framework, they put the idea out there for the larger machine learning community to build upon. This led to researchers and engineers hopping on the bandwagon and creating their own models.
These days, the world of GANs is a diverse ecosystem where one finds tons of frameworks that take inspiration from the original Generative Adversarial Network. In fact, if you saw some particularly exciting AI applications in the past five years, they were very likely powered by GANs.
Let’s look at some interesting examples.
Popular GAN models and architectures
1. Facebook’s ExGAN
Exemplar Generative Adversarial Networks, or ExGANs, were created by Brian Dolhansky and Cristian Canton Ferrer from Facebook.
ExGAN is sometimes called an “eye-opening GAN” because the paper that introduced it focused “on the particular problem of eye in-painting.” What the GAN does is it learns from exemplar data what the person’s eyes normally look like when open. This allows it to programmatically replace a particular person’s closed eyes with their open eyes in an image.
Needless to say, the capability can come useful in photo editing apps and similar software.

2. FSGAN (Face Swapping GAN)
FSGAN was developed by the Bar-Ilan University and the Open University of Israel. It’s a GAN used for face swapping and reenactment. One of the main benefits of this method is that it does not require prior training and can be used on any pair of people in real time.
One possible application could be using FSGAN in the movie industry. For instance, some sort of AI may have been used (but we don’t really know) to bring back to screen young Luke Skywalker, a Star Wars character played by Mark Hamill, who is now 69.
3. NVIDIA’s StyleGAN
Another highly-publicized GAN is NVIDIA’s StyleGAN. It gives you additional control over the generated image by allowing you to manipulate such effects as pose, skin tone, hair color and texture, small facial features, and others.
Based on predecessor ProGAN (also created by NVIDIA), StyleGAN begins by training the model on low-resolution images, gradually increasing resolution until a high-res visual is produced. Such a gradual approach (coupled with a bunch of other novelties introduced in StyleGAN) allows you to control parameters at different levels. The higher the image resolution, the more nuanced are the effects that can be tweaked:
- Coarse styles (4×4 – 8×8) control pose, hair, face shape;
- Middle styles (16×16 – 32×32) control facial features, eyes;
- Fine styles (64×64 – 1024×1024) control color scheme and micro features.
Thanks to feature disentanglement introduced in StyleGAN, changing a particular feature does not entail any collateral changes, which allows for granular fine-tuning.

StyleGAN has lots of potential applications, from mass-producing anime characters to populating an online catalogue with pictures of merchandise items to creating realistic backgrounds in photos with furniture pieces.
4. Age-cGAN
Conditional GANS (cGANS) are an extension of the GAN model that allows the generation of images that have certain conditions.
In 2017, Grigory Antipov, Moez Baccouche, and Jean-Luc Dugelay proposed a cGAN network called Age-cGAN that, once trained, can perform automatic face aging while preserving the person’s identity. According to the researchers, the method has plenty of applications, like cross-age face recognition, finding lost children, and entertainment, among others.

5. CycleGAN
To solve the problem of image-to-image translation (day to night, black-and-white to color, aerial to map, etc.) researchers at Berkeley AI Research Laboratory proposed Pix2Pix GAN in 2016. The task boils down to predicting pixels from pixels, hence the name.
The method was then further improved upon by some of the same researchers and a few others, including Jun-Yan Zhu and his colleagues, who created CycleGAN. Because it adheres to cyclic consistency, CycleGAN can learn the mapping from X space to Y space using unpaired images. This leads to better outcomes.

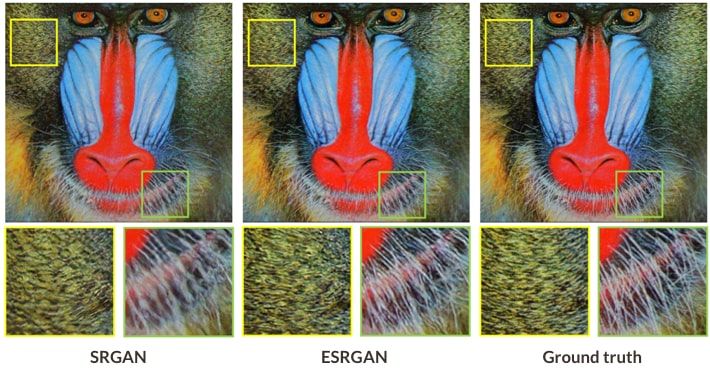
6. ESRGAN
ESRGAN stands for Enhanced Super-Resolution GAN. It’s an improvement to the original SRGAN (Super-Resolution GAN) network proposed by Ledig, and others. ESRGAN essentially does the same thing as SRGAN – it improves the resolution of low-res images. However, it does it slightly better, thanks to improvements like the introduction of Residual-in-Residual Dense Block, among others.
7. BigGAN
BigGAN is the type of GAN that solves the problem of synthesizing high-resolution, high-fidelity images with set characteristics. In their paper “Large Scale GAN Training for High Fidelity Natural Image Synthesis,” researchers from Heriot-Watt University and Google’s DeepMind write:
Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal.
In their attempt to improve the quality and increase the variety of generated images, researchers increase batch sizes and layer widths, dramatically improving the model’s Inception Score.

Perhaps it’s also worth mentioning that BigGAN builds on previous achievements by SA-GAN (Self-Attention GAN) that introduces an attention map and applies it to feature maps, allowing the D-model and the G-model to pay attention to different parts of the image.
Since BigGAN indefinitely nears the advent of synthetically-produced on-demand imagery, perhaps soon we won’t need stock photography sites any longer. Only time will show.
In Conclusion
While our article is focused mostly on the application of Generative Adversarial Networks in Computer Vision, it is by no means limited to CV only. There has been research around using GANs in NLP (natural language processing), cryptography, genetics, and other spheres of human life.
All in all, GANs seem a promising part of deep learning technologies and one that may lead to significant advancements in AI in the near future.
Further reading:
Recent Progress on Generative Adversarial Networks (GANs): A Survey
GAN topics on “The Machine Learning Mastery” by Jason Brownlee
Related Blogs

Off-the-shelf AI: adopting much-hyped technology with minimum risk
LEARN MORE

{kind=link}