
ObjectStyle has a portfolio of open-source products. In fact, it was a successful open-source project, Apache Cayenne, that led to the creation of this company. You may say that ObjectStyle owes its very existence to the world of open software.
With time, our portfolio grew, and it now includes Apache Cayenne, Bootique, Agrest, and DFLib open-source solutions. We’d like to tell the story behind each of these projects and explain why we created them.
Apache Cayenne
First release: 2002
What it is: A Java object-to-relational mapping framework
Closest alternatives: Hibernate, JPA
Key features: lazy resolution of object graph, advanced object query language, single-call commits, and smooth, nearly automated modeling workflow
In the early 2000’s, ORM (object-relational mapping) was a fairly new approach to writing apps among Java programmers. Andrus Adamchik and a group of co-workers realized that there were no good ORMs in Java, let alone ones under an open-source license. So they ended up writing their own framework dubbed “Cayenne.”
Cayenne was warmly received by developers and attracted some high-profile organizations like the National Hockey League, Nike, Unilever, US Federal Government, and the Law Library of Congress. To help out early Cayenne adopters, Andrus Adamchik started a consultancy called ObjectStyle in 2002.
In 2006, Cayenne joined the Apache Software foundation. The name became Apache Cayenne and Andrus Adamchik was appointed VP of the Apache Software Foundation for this project.
As of 2020, Cayenne has gone through a series of redesigns and major releases. Over the years, we’ve kept it up to date with the latest ORM programming trends and the latest versions of Java. Despite its twenty-year history, Cayenne is a modern instrument, ready to meet anyone’s ORM needs.
Bootique
First release: 2015
What it is: A minimally-opinionated framework for runnable Java apps
Closest alternatives: Spring Boot, Dropwizard
Key features: no-magic modularity, dependency injection, CLI, ease of integration, small app footprint, fast startup.
At the time Bootique was created, an industry shift was taking place: the Java community wanted to move away from old, bulky J2EE solutions to lightweight, container-free applications. Our vision was of a simple Java app launcher that can run apps with just the main() method.
The two products at the forefront of the “container-less” movement were Dropwizard and Spring Boot. However, Dropwizard was a single-purpose framework focusing primarily in REST services, while Spring Boot was bulky, slow, and unpredictable. ObjectStyle needed something more flexible (unlike Dropwizard), lightweight, and transparent (unlike Spring Boot).
That was how Project Bootique was born. Bootique has a flexible modular structure, which allows developers to effortlessly sync any app/module with the core. (See a list of modules supported out of the box.) It also gives one full control over the dependencies.
In 2016, the OverOps blog named Bootique #1 upcoming Java project to try out on Github. More than 500 Github users starred Bootique by the end of 2016, and that number doubled to over 1,000 Github stars by 2018.
Bootique was originally built on top of Google Guice as a dependency injection technology (see Guice Stories – Part 1 and Guice Stories – Part 2 by Andrus Adamchik). Since 2.0, we have switched to our own dependency management mechanism, bootique-di, making it even lighter and faster:
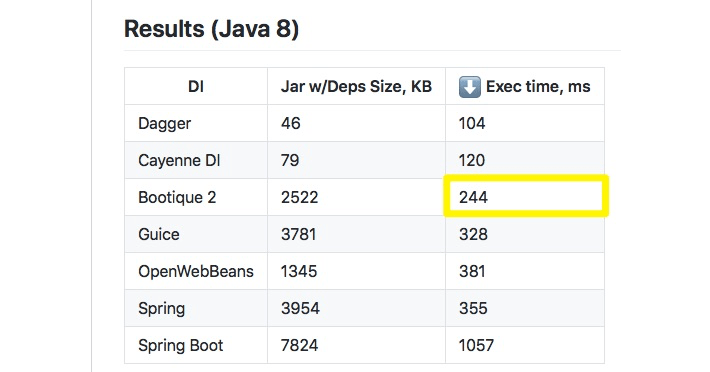
Another beauty of Bootique is that it’s suitable for all kinds of apps, from small microservices to large monoliths with lots of dependencies. We’ve seen success stories from Bootique users across the board.
Agrest
First release: 2014
What it is: A flexible model-driven REST data service framework
Closest alternative: GraphQL
Key features: A Java framework for building custom data backends with reach query and update functionality. Common set of REST API controls for filtering, sorting, and paginating that can be applied to any data model. Built-in support for relational database backends, extensions API to add other backends. Object- and attribute-level security.
There are two common problems with REST API: it returns either too much or too little data per request. Typical REST APIs give client side developers very little or no control over the shape and size of the returned data, nor do they allow to perform requests across aggregate boundaries.
To solve these two problems, we created Agrest. It includes a simple HTTP-based protocol to navigate object graphs (such as ORM models), as well as a server-side framework to serve the requested data. It means that the Client can get as little or as much data as it needs. Developers can tailor their requests to match user interface requirements. For instance, one can get a lot of data for a desktop screen or little data for a mobile app.
Agrest (formerly LinkREST) was first launched in 2014. Shortly after that, Facebook unveiled GraphQL – a tool with similar graph query capabilities. While both frameworks are based on the same philosophy, they take different approaches to building the object graph. In GraphQL, developers need to create custom schemas and data resolvers. In Agrest, REST service graphs are automatically generated from the business object model, and data retrieval is delegated to the underlying ORM or another such mechanism. Programming a flexible Agrest endpoint requires just a few lines of code.
DFLib
First release: 2019
What it is: a lightweight Java implementation of the DataFrame structure common in data science.
Closest alternatives: Python pandas, Spark DataFrame
Key features: working with any kind of data using a generic table-like object. The ability to perform data transformations in memory in any Java app with no special external infrastructure. Rich set of data transformation operations (join, concatenation, sort, filter, projection, aggregation), combining data from multiple data sources (CSV, databases, etc.). Support for Jupyter Notebook.
Andrus Adamchik first envisioned DFLib as a tool that would bring the DataFrame structure to Java. DataFrames are widely used in other programming languages like R, Python, and Scala. For example, the Python community has pandas – a library that lets one work with Excel-like tables where data can be edited and manipulated. DFLib allows developers to do the same, only for Java models and applications.
In DFLib, DataFrames can be loaded from any data source (databases, CSV, JSON, etc.), and then combined, filtered, aggregated, etc. in memory and then visualized or sent back to a datastore, all with a simple fluent Java API.
In Conclusion
Have you tried any of the above mentioned open-source technologies? Please let us know in the comments!
Related Blogs

Changing the World from GitHub: 15 Open-Code Initiatives That Drive Social Change
LEARN MORE