
Both DevOps and microservice architectures help development teams deliver better software faster. However, when the two come together, new challenges arise.
DevOps Issues Caused by Microservices
Although DevOps and microservices are two practices that usually go hand in hand, an organization may be practicing DevOps despite having a monolith application. Plus, some teams approach service-based architectures with their old “monolithic” mentality, which results in a product that’s essentially a monolith disguised as a set of microservices.
So, what unique challenges do DevOps engineers face when dealing with microservices?
1. Communication Issues

In a monolithic app, its components are tightly-coupled, share the same database, “speak” each other’s (programming) language, and are scaled and deployed together. Whereas in a microservice-based application, each service is an independent unit that, ideally, uses a separate database, can be written in any language, and can be scaled and deployed on its own.
A common mistake that many developers make is they don’t bother to truly separate microservices from one another. When companies adopt microservices, some do it in a way that’s really still a monolith, as Google Cloud’s Kelsey Hightower says (emphasis added):
Most people say, “Look, we lost all of our discipline in the monolith. We just started creating classes, this person went and bought the ‘Gang of Four’ book, came back and started doing design patterns and then QUIT, so half our codebase is doing this thing over here…”
So now it’s a nightmare. Now the codebase is so bad, and you say, “You know what we should do? We should break it up. We’re gonna break it up and somehow find the engineering discipline we never had in the first place.” And then what they end up doing is creating 50 deployables, but it’s really a distributed monolith.

So in a poorly-designed setup, microservices behave as if they still were parts of a monolith. This causes all sorts of networking and communication problems.
How to solve this
- Strive for loose coupling
Avoid tight coupling of classes, data (no shared DBs!), and interfaces where possible. Tight coupling is an anti-pattern in service-oriented architectures.
- Use asynchronous communication
In a sequence of synchronous calls, the slowest service bogs down the entire process. You want to minimize communication between internal microservices and use async communication instead.
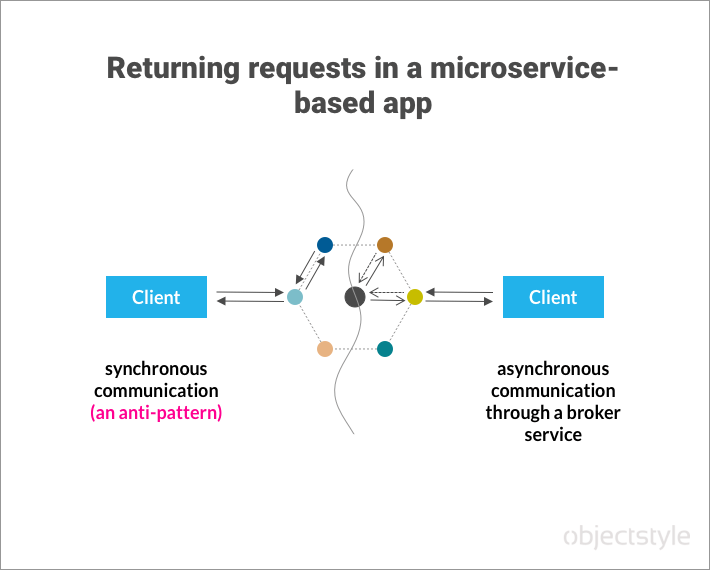
To implement asynchronous calls, you can use event-driven architecture where an “event” means a “simple change in state,” and services can publish or consume events (via subscriptions) without having to know who the publisher is or who may be consuming their data.
From AWS’s website:
Event-driven architectures have three key components: event producers, event routers, and event consumers. A producer publishes an event to the router, which filters and pushes the events to consumers. Producer services and consumer services are decoupled, which allows them to be scaled, updated, and deployed independently.
2. Limited Observability
A related challenge is to perform proper monitoring of an application built with microservices. The difficulty occurs due to network complexity, which makes it hard to isolate failures and perform debugging.
How to solve this
You can reduce networking problems (as well as debugging issues) if you invest in core tooling and application-level abstractions, believes Matt Klein of Lyft, the prime creator of the Envoy application networking system. He adds:
Microservices force us to think extremely carefully about the right abstractions with regard to feature ownership, data ownership, and communication language/API design. Even if all services are hosted in a monorepo (and I hope they aren’t!), they will never all be deployed at the same time, making backwards compatibility an ongoing concern. There is simply no easy way to fix abstraction mistakes without complex migrations that consume valuable engineering time.
Besides Envoy, there are tools like Twitter’s Zipkin and X-Ray by AWS that help developers and operations professionals with tasks like tracing and debugging.
Another recipe for efficient microservice monitoring was suggested by Yunwei Bang of Qiniu Cloud, a Chinese version of AWS:
When we first started monitoring, there were hundreds of instances monitoring the same keyword, and hundreds of text messages were received after the failure, because each instance sent a text message. At this time, serious fatal alarms will not be seen, because the mobile phone information has exploded, so to classify the alarms, accurate alarms, the most important thing is to try to make the failure die before it occurs. Therefore, when doing monitoring, it is necessary to judge the fault in advance, first automate the processing, and then see if it needs to be handled manually, and then through human intervention, the failure can be effectively destroyed before it occurs.
3. Difficulty Scaling Microservices
If you find it difficult to scale microservices, this is another symptom of the same issues we already mentioned:
- Tight coupling of individual services (that otherwise should know as little as possible about one another)
- Synchronous communication
- The system being essentially a “distributed monolith” rather than a microservices architecture
How to solve this
To enable maximum scalability, make sure your services are truly separated.
4. Achieving Consistency

In a monolith, all parts of the application share the same knowledge about the state of the system at all times – after all, they are closely connected. In a distributed system, each microservice uses its own database, so it may be challenging to propagate knowledge across the entire system.
How to solve this
To achieve data consistency across microservices, you can use one of the following approaches:
- Distributed transactions
- Eventual consistency in an event-driven architecture
Since distributed transactions have their drawbacks, eventual consistency can help overcome speed and availability limitations. This is particularly important in the enterprise setting.
What is eventual consistency, exactly?
Eventual consistency is best understood through its opposite, which is strong consistency (a.k.a. immediate consistency). Strong consistency occurs when you have microservices exchange data in a specific order. So when they fail, they fail together. Alternatively, eventual consistency means that you let events run in parallel and wait for them to eventually become completed across all applicable data endpoints.
5. API Updates
An API (application programming interface) is essentially a contract between service A that makes its data available to service(s) XYZ that may consume that data. The contract defines the rules according to which the data is provided (types of data, formats, protocols, etc.)
However, services evolve, so their APIs may change over time. Your microservice-based app may be either the publisher of the consumer of API data.
As a publisher, you need to make sure that the services that rely on your data can still function, although your API has changed. As a consumer of APIs, you need to decide when to update your services to reflect API changes, even though sometimes you may not need to do that immediately.
How to solve this
Proper API versioning and providing backwards compatibility ensures that the changes you make to an API do not cause issues in services that depend on that API.
Another issue with APIs is that they sometimes worsen performance because of intense communication. Hence, one should try to avoid chatty interfaces that require multiple calls per task and consider using lighter message formats.
TL; DR
The very nature of microservices brings the potential to cause issues that didn’t exist in monolithic systems. Software engineers should watch out for things like communication problems, state inconsistencies, debugging difficulties, scalability discrepancies, and API updates. In general, loose coupling, asynchronous communication, and approaches like event-based programming and eventual consistency should help you deal with these challenges.
Related Blogs

Real benefits of adjoining DevOps culture to your Agile processes (supported by hard numbers)
LEARN MORE